










1.點擊下面按鈕復制微信號
點擊復制微信號
上海威才企業管理咨詢有限公司


微信咨詢&報名

本課程專注于金融行業的風控識別與風控預測模型,面向數據分析部等專門負責數據分析與建模的人士。
本課程的主要目的是,培養學員的大數據意識和大數據思維,掌握常用的數據分析方法和數據分析模型,并能夠用于對客戶行為作分析和預測,提升學員的數據分析綜合能力。
通過本課程的學習,達到如下目的:
1、 掌握數據分析和數據建模的基本過程和步驟
2、 掌握數據分析框架的搭建,及常用分析方法
3、 掌握業務的影響因素分析常用的方法
4、 掌握常用客戶行為預測模型,包括邏輯回歸、決策樹、神經網絡、判別分析等等,以及分類模型的優化
5、 掌握金融行業信用評分卡模型,構建信用評分模型
內容 2天 4天 核心數據思維 √ √ 數據分析過程 √ √ 用戶行為分析 √ √ 數據分析框架 √ √ 異常數據識別 √ √ 影響因素分析 √ √ 數據建模基礎 √ 客戶行為預測 √ 市場客戶細分 √ 信用卡評分模型 √ 數據建模實戰 √ 課程收益 PROGRAM BENEFITS
課程收益 PROGRAM BENEFITS
問題:什么是數據思維?大數據決策的底層邏輯以及決策依據是什么?
1、 大數據的本質
‐ 數據,是事物發展和變化過程中留下的痕跡
‐ 大數據不在于量大,而在于全(多維性)
‐ 業務導向還是技術導向
2、 大數據決策的底層邏輯(即四大核心價值)
‐ 探索業務規律,按規律來管理決策
案例:客流規律與排班及最佳營銷時機
案例:致命交通事故發生的時間規律
‐ 發現運營變化,定短板來運營決策
案例:考核周期導致的員工月初懈怠
案例:工序信號異常監測設備故障
‐ 理清要素關系,找影響因素來決策
案例:情緒對于股市漲跌的影響
案例:為何升職反而會增加離職風險?
‐ 預測未來趨勢,通過預判進行決策
案例:海爾利用數據來預測空調故障,實現事前檢修
案例:保險公司的車險預測與個性化保費定價
3、 大數據決策的三個關鍵環節
‐ 業務數據化:將業務問題轉化為數據問題
‐ 數據信息化:提取數據中的業務規律信息
‐ 信息策略化:基于規律形成業務應對策略
案例:用數據來識別喜歡賺“差價”的營業員
1、 數據分析的六步曲
2、 步驟1:明確目的,確定分析思路
‐ 確定分析目的:要解決什么樣的業務問題
‐ 確定分析思路:分解業務問題,構建分析框架
3、 步驟2:收集數據,尋找分析素材
‐ 明確數據范圍
‐ 確定收集來源
‐ 確定收集方法
4、 步驟3:整理數據,確保數據質量
‐ 數據質量評估
‐ 數據清洗、數據處理和變量處理
‐ 探索性分析
5、 步驟4:分析數據,尋找業務答案
‐ 選擇合適的分析方法
‐ 構建合適的分析模型
‐ 選擇合適的分析工具
6、 步驟5:呈現數,解讀業務規律
‐ 選擇恰當的圖表
‐ 選擇合適的可視化工具
‐ 提煉業務含義
7、 步驟6:撰寫報告,形成業務策略
‐ 選擇報告種類
‐ 完整的報告結構
演練:產品精準營銷案例分析
‐ 如何搭建精準營銷分析框架
問題:數據分析方法的種類?分析方法的不同應用場景?
1、 業務分析的三個階段
‐ 現狀分析:通過企業運營指標來發現規律及短板
‐ 原因分析:查找數據相關性,探尋目標影響因素
‐ 預測分析:合理配置資源,預判業務未來的趨勢
2、 常用的數據分析方法種類
3、 統計分析基礎
4、 基本分析方法及其適用場景
‐ 對比分析(查看數據差距,發現事物變化)
演練:分析理財產品受歡迎情況及貢獻大小
演練:用戶消費水平差異分析,提取優質客戶特征
‐ 分布分析(查看數據分布,探索業務層次)
案例:銀行用戶的消費層次/消費檔次分析
演練:客戶年齡分布/收入分布分析
‐ 結構分析(查看指標構成,評估結構合理性)
案例:收入結構分析/成本結構分析
案例:動態結構分析
‐ 趨勢分析(查看變化趨勢,了解季節周期性)
案例:營業廳客流量規律與排班
案例:用戶活躍時間規律/產品銷量的淡旺季分析
演練:產品訂單的季節周期性規律
‐ 交叉分析(從多個維度的數據指標分析)
演練:不同客戶的產品偏好分析
演練:銀行用戶違約的影響因素分析
問題:如何才能全面/系統地分析而不遺漏?如何分解和細化業務問題?
1、 分析框架來源于業務模型
‐ 商業目標(粗粒度)
‐ 分析維度/關鍵步驟
‐ 業務問題(細粒度)
‐ 涉及數據/關鍵指標
2、 常用的業務模型:PEST/5W2H/SWOT/PDCA/AARRR…
研討:結合公司業務情況,選取業務目標,構建系統的數據分析框架
1、 反欺詐識別的重點內容
‐ 如何識別異常數據
‐ 如何查找影響因素
‐ 如何提取欺詐用戶的特征
‐ 如何預測用戶的欺詐行為
2、 異常數據的定義
3、 異常數據的檢測方法
‐ 基于統計法:標準差法、四分位距法、離群點檢測算法
‐ 基于機器學習:回歸、聚類等
4、 異常數據處理方法
演練:各種異常數據識別
問題:如何做原因分析?比如價格是否可用于產品銷量?影響用戶違約的關鍵因素是什么?
1、 數據預處理vs特征工程
2、 特征選擇常用方法
‐ 相關分析、方差分析、卡方檢驗
3、 相關分析(衡量兩數據型變量的線性相關性)
‐ 相關分析簡介
‐ 相關分析的應用場景
‐ 相關分析的種類
◢ 簡單相關分析
◢ 偏相關分析
◢ 距離相關分析
‐ 相關系數的三種計算公式
◢ Pearson相關系數
◢ Spearman相關系數
◢ Kendall相關系數
‐ 相關分析的假設檢驗
‐ 相關分析的四個基本步驟
演練:營銷費用會影響銷售額嗎?影響程度如何量化?
演練:哪些因素與產品銷量有顯著的相關性
演練:影響用戶消費水平的因素會有哪些
‐ 偏相關分析
◢ 偏相關原理:排除不可控因素后的兩變量的相關性
◢ 偏相關系數的計算公式
◢ 偏相關分析的適用場景
4、 方差分析(衡量類別變量與數值變量間的相關性)
‐ 方差分析的應用場景
‐ 方差分析的三個種類
◢ 單因素方差分析
◢ 多因素方差分析
◢ 協方差分析
‐ 單因素方差分析的原理
‐ 方差分析的四個步驟
‐ 解讀方差分析結果的兩個要點
案例:擺放位置與銷量有關嗎
演練:客戶學歷對消費水平的影響分析
‐ 多因素方差分析原理
‐ 多因素方差分析的作用
‐ 多因素方差結果的解讀
案例:廣告形式、地區對銷售額的影響因素分析
演練:銷售員的性別、技能級別對銷量有影響嗎
‐ 協方差分析原理
‐ 協方差分析的適用場景
演練:排除用戶收入,其余哪些因素對銷量有顯著影響?
5、 列聯分析/卡方檢驗(兩類別變量的相關性分析)
‐ 交叉表與列聯表:計數值與期望值
‐ 卡方檢驗的原理
‐ 卡方檢驗的幾個計算公式
‐ 列聯表分析的適用場景
案例:產品類型對客戶流失的影響分析
案例:用戶學歷對產品類型偏好的影響分析
研討:行業/規模對風控的影響分析
1、 預測建模六步法
‐ 選擇模型:基于業務選擇恰當的數據模型
‐ 特征工程:選擇對目標變量有顯著影響的屬性來建模
‐ 訓練模型:采用合適的算法對模型進行訓練,尋找到最優參數
‐ 評估模型:進行評估模型的質量,判斷模型是否可用
‐ 優化模型:如果評估結果不理想,則需要對模型進行優化
‐ 應用模型:如果評估結果滿足要求,則可應用模型于業務場景
2、 數據挖掘常用的模型
‐ 定量預測模型:回歸預測、時序預測等
‐ 定性預測模型:邏輯回歸、決策樹、神經網絡、支持向量機等
‐ 市場細分:聚類、RFM、PCA等
‐ 產品推薦:關聯分析、協同過濾等
‐ 產品優化:回歸、隨機效用等
‐ 產品定價:定價策略/最優定價等
3、 特征工程/特征選擇/變量降維
‐ 基于變量本身特征
‐ 基于相關性判斷
‐ 因子合并(PCA等)
‐ IV值篩選(評分卡使用)
‐ 基于信息增益判斷(決策樹使用)
4、 模型評估
‐ 模型質量評估指標:R^2、正確率/查全率/查準率/特異性等
‐ 預測值評估指標:MAD、MSE/RMSE、MAPE、概率等
‐ 模型評估方法:留出法、K拆交叉驗證、自助法等
‐ 其它評估:過擬合評估、殘差檢驗
5、 模型優化
‐ 優化模型:選擇新模型/修改模型
‐ 優化數據:新增顯著自變量
‐ 優化公式:采用新的計算公式
‐ 集成思想:Bagging/Boosting/Stacking
6、 常用預測模型介紹:回歸、時序、分類
問題:如何評估客戶購買產品的可能性?如何預測客戶的購買行為?如何提取某類客戶的典型特征?如何向客戶精準推薦產品或業務?
1、 分類模型概述及其應用場景
2、 常見分類預測模型
3、 邏輯回歸(LR)
‐ 邏輯回歸的適用場景
‐ 邏輯回歸的模型原理
‐ 邏輯回歸分類的幾何意義
‐ 邏輯回歸的種類:二項、多項
‐ 如何解讀邏輯回歸方程
‐ 多項邏輯回歸/多分類邏輯回歸
案例:多品牌選擇模型分析(多項邏輯回歸)
4、 分類決策樹(DT)
問題:如何預測客戶行為?如何識別潛在客戶?
風控:如何識別欠貸者的特征,以及預測欠貸概率?
客戶保有:如何識別流失客戶特征,以及預測客戶流失概率?
‐ 決策樹分類簡介
演練:識別銀行欠貨風險,提取欠貸者的特征
‐ 決策樹分類的幾何意義
‐ 構建決策樹的三個關鍵問題
◢ 如何選擇最佳屬性來構建節點:熵/基尼系數、信息增益
◢ 如何分裂變量:多元/二元劃分、最優切割點
◢ 修剪決策樹:剪枝原則、預剪枝與后剪枝
‐ 構建決策樹的四個算法
‐ 如何選擇最優分類模型?
案例:商場用戶的典型特征提取
案例:客戶流失預警與客戶挽留
案例:識別拖欠銀行貨款者的特征,避免不良貨款
‐ 多分類決策樹
案例:識別不同理財客戶的典型特征,實現精準推薦
‐ 決策樹模型的保存與應用
5、 人工神經網絡(ANN)
‐ 神經網絡的結構
‐ 神經網絡基本原理
‐ 神經網絡分類的幾何意義
‐ 神經網絡的建立步驟及實現算法
‐ 神經網絡的關鍵問題
案例:評估銀行用戶拖欠貨款的概率
6、 支持向量機(SVM)
‐ SVM基本原理
‐ 線性可分問題:最大邊界超平面
‐ 線性不可分問題:特征空間的轉換
‐ 維災難與核函數
1、模型的評估指標
‐ 兩大矩陣:混淆矩陣,代價矩陣
‐ 六大指標:Acc,P,R,Spec,F1,lift
‐ 三條曲線:
◢ ROC曲線和AUC
◢ PR曲線和BEP
◢ KS曲線和KS值
2、模型的評估方法
‐ 留出法(Hold-Out)
‐ 交叉驗證法(k-fold cross validation)
‐ 自助采樣法(Bootstrapping)
1、模型的優化思路
2、集成算法基本原理
‐ 單獨構建多個弱分類器
‐ 多個弱分類器組合投票,決定預測結果
3、集成方法的種類:Bagging、Boosting、Stacking
4、Bagging集成:隨機森林RF
‐ 數據/屬性重抽樣
‐ 決策依據:少數服從多數
5、Boosting集成:AdaBoost模型
‐ 基于誤分數據建模
‐ 樣本選擇權重更新公式
‐ 決策依據:加權投票
6、高級模型介紹與實現
‐ GBDT梯度提升決策樹
‐ XGBoost
‐ LightGBM
問題:我們的客戶有幾類?各類特征是什么?如何實現客戶細分,開發符合細分市場的新產品?如何提取客戶特征,從而對產品進行市場定位?
1、 市場細分的常用方法
‐ 有指導細分
‐ 無指導細分
2、 聚類分析
‐ 如何更好的了解客戶群體和市場細分?
‐ 如何識別客戶群體特征?
‐ 如何確定客戶要分成多少適當的類別?
‐ 聚類方法原理介紹
‐ 聚類方法作用及其適用場景
‐ 聚類分析的種類
◢ K均值聚類
◢ 層次聚類
◢ 兩步聚類
‐ K均值聚類(快速聚類)
‐ 層次聚類(系統聚類):發現多個類別
‐ 兩步聚類
演練:劃分合適的客戶群,提取不同客戶群的典型特征
3、 客戶細分與PCA分析法
‐ PCA主成分分析的原理
‐ PCA分析法的適用場景
演練:利用PCA對客戶群進行細分
1、 信用評分卡模型簡介
2、 評分卡的關鍵問題
3、 信用評分卡建立過程
‐ 篩選重要屬性
‐ 數據集轉化
‐ 建立分類模型
‐ 計算屬性分值
‐ 確定審批閾值
4、 篩選重要屬性
‐ 屬性分段
‐ 基本概念:WOE、IV
‐ 屬性重要性評估
5、 數據集轉化
‐ 連續屬性最優分段
‐ 計算屬性取值的WOE
6、 建立分類模型
‐ 訓練邏輯回歸模型
‐ 評估模型
‐ 得到字段系數
7、 計算屬性分值
‐ 計算補償與刻度值
‐ 計算各字段得分
‐ 生成評分卡
8、 確定審批閾值
‐ 畫K-S曲線
‐ 計算K-S值
‐ 獲取最優閾值
案例:構建銀行小額貸款的用戶信用模型
1、電信業客戶流失預警和客戶挽留模型實戰
2、銀行欠貸風險預測模型實戰
3、銀行信用卡評分模型實戰
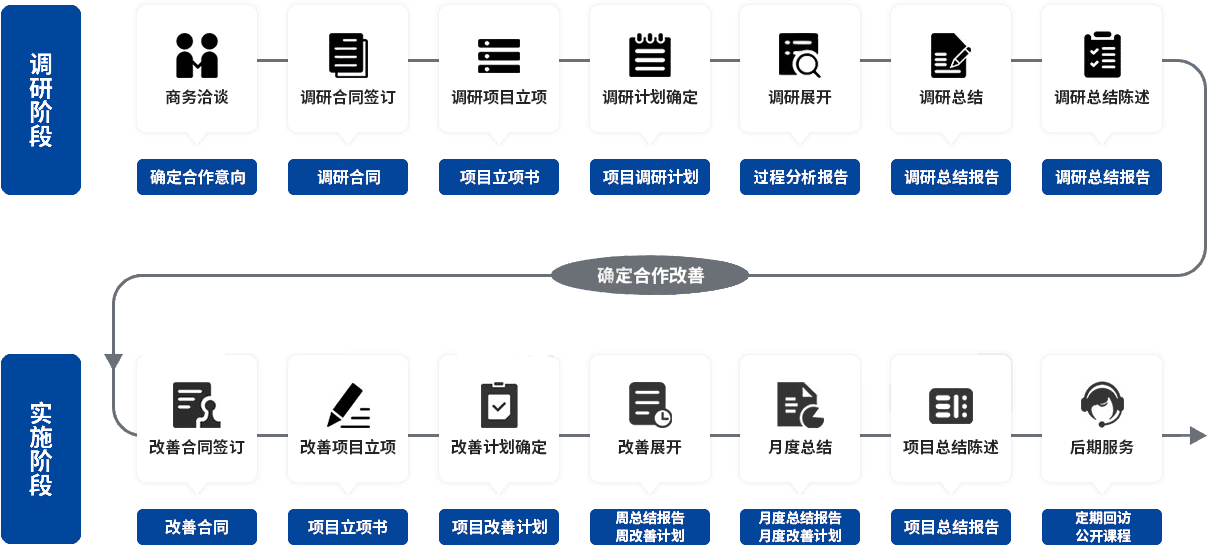
結束:課程總結與問題答疑。



































聯系電話:4006-900-901
微信咨詢:威才客服
企業郵箱:shwczx@shwczx.com

深耕中國制造業
助力企業轉型
2021年度咨詢客戶數
資深實戰導師
客戶滿意度
續單和轉介紹

咨詢熱線
星期一至星期五 8:00~20:30 (添加微信注明來意)